姿を現す次世代FPGA、400Gネットワーク支える基盤に:プログラマブルロジック FPGA
次世代FPGAの姿がいよいよ鮮明に見え始めた。ハイエンドFPGAは、ネットワーク機器の高性能化に対応すべく、入出力帯域幅を大幅に広げる。そうした中、ハイエンド品に適用する製造プロセス技術の微細化競争で新たな動きがあった。微細化は、ハイエンド品の応用可能範囲に大きな影響を及ぼす要素だ。微細化が進むのはハイエンド品だけではない。異なる市場を狙う不揮発性FPGAでも、次世代品がその姿を次第に現し始めている。
次世代FPGAの姿がいよいよ鮮明に見え始めた。ハイエンドFPGAは、ネットワーク機器の高性能化に対応すべく、入出力帯域幅を大幅に広げる。そうした中、ハイエンド品に適用する製造プロセス技術の微細化競争で新たな動きがあった。微細化は、ハイエンド品の応用可能範囲に大きな影響を及ぼす要素だ。微細化が進むのはハイエンド品だけではない。異なる市場を狙う不揮発性FPGAでも、次世代品がその姿を次第に現し始めている。
FPGA市場の2強であるアルテラとザイリンクスは、ユーザーが任意の論理回路を実装できるプログラム領域の基本素子としてSRAMを利用したFPGAを主力製品としており、次世代品では半導体プロセス技術を現行品が使う40nm世代から28nm世代へと微細化する。次世代品ではまず、「超ハイエンド」の用途を狙う。具体的には、今後開発が進むと期待される、数百Gビット/秒と極めて高いデータ伝送速度に対応する通信機器だ。そのため両社ともに、FPGAに混載する高速シリアルトランシーバの高性能化に力を注ぐ。この開発方針そのものは2010年2月以降、両社が順次表明していたが、2010年11月になって、いよいよ具体的な製品仕様の発表が始まった。
そうした中、伏兵が現れた。SRAMベースのFPGAを手掛ける新興ベンダーで、米国に本社を置くAchronix Semiconductor(アクロニクスセミコンダクター)である。マイクロプロセッサの雄インテルと手を組み、22nm世代のプロセス技術を適用したハイエンドFPGAを投入すると2010 年11月に発表したのだ。アルテラとザイリンクスが常に微細化の最先端をいくという構図が長年続いてきたFPGA市場において、新興ベンダーが微細化で先行するのは今回が初めてになる。
こうした動きの一方で、FPGAの中堅ベンダー2社も2010年11月にそれぞれ次世代品を発表した。1社はアクテル(2010年10月に米国の半導体ベンダーのMicrosemi(マイクロセミ)に買収され、現在は同社の「SoCプロダクト部門」として統合済み)で、もう1社はラティスセミコンダクターである。2社は、プログラム領域の基本素子にフラッシュメモリセルを使う不揮発性FPGAを得意としており、次世代品では現行の130nmから65nmへと微細化を進める。最大手2社が供給するSRAMベースのハイエンドFPGAとは違った用途を狙っており、それゆえに製品仕様も大きく異なっている。
ハイエンド品は帯域幅が第1要件
すべては帯域幅のために――。アルテラが28nm世代のハイエンド品「Stratix V」の発表時に掲げたフレーズである。FPGAが単位時間当たりに入出力できるデータの量を飛躍的に増やす。それこそが、28nm世代品の開発の主眼だという。
背景には、ネットワークを介してやりとりされるデータの量が爆発的に増大しているという事実がある。「ネットワーク接続機能を備えたモバイル機器が普及し、第3世代携帯電話ネットワークやモバイルバックホール(数多くの携帯電話基地局を収容してモバイルコアネットワークにつなぐアクセス網)の整備も進んでいる。また、FTTH(家庭向け光データ回線)の利用者が増加している。これらの結果、モバイルとビデオのトラフィックが急増中だ。さらにクラウドコンピューティングの立ち上がりも、ネットワークを流れるデータ量の増大に拍車をかけている」(アルテラ)。
ザイリンクスも、28nm世代のハイエンド品の開発に当たって、こうした市場の要求を念頭に置いた。同社は、通信機器大手メーカーのシスコシステムズが発表した次のような予測を引用する(図1)。「2009年から2014年にかけて、ネットワークを流れるデータのトラフィックは平均で年率34%ずつ増加すると見込まれる。2009年は1カ月当たり15E(エクサ)バイトだったトラフィックが、2014年には4倍以上の64Eバイトまで膨らむことになる」という予測である。
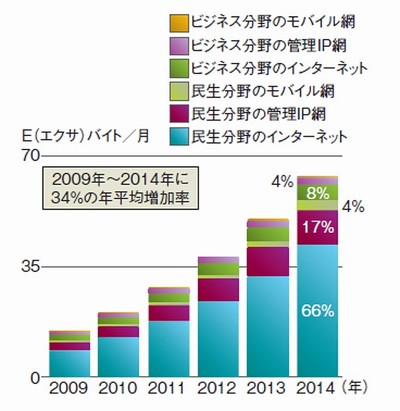 図1 ネットワークを流れるデータは年率34%で増加 各種ネットワークを流れる1カ月当たりパケットデータ量の予測である。2009年〜2014年の年平均増加率は34%と見込まれる。民生機器からのインターネット利用の増大が特に大きく寄与する。出典:シスコシステムズ、「Cisco Visual Networking Index:Forecast and Methodology, 2009−2014」(2010年6月2日発表)
図1 ネットワークを流れるデータは年率34%で増加 各種ネットワークを流れる1カ月当たりパケットデータ量の予測である。2009年〜2014年の年平均増加率は34%と見込まれる。民生機器からのインターネット利用の増大が特に大きく寄与する。出典:シスコシステムズ、「Cisco Visual Networking Index:Forecast and Methodology, 2009−2014」(2010年6月2日発表)これに対応するためには、通信機器の帯域幅を現行から大幅に拡大しなければならない。「2014年以降、データ伝送速度が400Gビット/秒や1T(テラ)ビット/秒と極めて高いラインカード(通信ボード)を収容し、システム全体では数Tビット/秒のデータ伝送に対応できるような、次世代の通信機器が登場することになるだろう。しかも、こうした通信機器は、次世代に移行してもサイズや消費電力を変えることは許されない。変えるならば、より小さく。これが必須条件になる」(ザイリンクス)。
広帯域化の鍵は高速シリアルが握る
サイズや消費電力の増大を抑えつつ、データの入出力帯域幅を大幅に拡張する。これを実現する鍵を握るのが、高速シリアルトランシーバだ。通信機器向けのハイエンドFPGAには、従来からSERDES(シリアライザ/デシリアライザ)機能付きの高速シリアルトランシーバ回路が混載されていた。このトランシーバ回路当たりのデータ伝送速度を高めなければならない。
例えばアルテラは現在、11.3Gビット/秒動作の高速シリアルトランシーバを集積した40nm世代のFPGA「Stratix IV GT」を出荷している。仮にこのトランシーバで入力と出力それぞれに400Gビット/秒の帯域幅を確保しようとすると、80チャネルものトランシーバを集積して10Gビット/秒で動作させる必要がある。「チップ面積や発熱が大きくなり現実的ではない」(同社)。しかもこのように伝送速度が比較的低いトランシーバを数多く使う手法では、FPGAに外付けする光/電気変換モジュールの数も多くなり、システム全体のコストやサイズを押し上げる要因になってしまう。
そこでアルテラは、28nm世代のハイエンドFPGA「Stratix V」で、28Gビット/秒動作の新型高速シリアルトランシーバを集積する品種群「Stratix V GT」を2010年4月に発表している。仮に32チャネルをFPGAに集積できれば、それらを25Gビット/秒で動かせばよい。高速シリアルトランシーバのチャンネル数を一気に減らせる。外付けの光/電気変換モジュールは高速な品種が必要になるものの、個数を大幅に抑えられるので、全体的に見ればコストやサイズの低減が期待できる。
1個のFPGAで400G対応が可能に
ザイリンクスも、アルテラに続いて2010年6月に、28nm世代のハイエンドFPGA「Virtex-7」で28Gビット/秒対応の高速シリアルトランシーバを搭載することを表明していた。そして2010年11月になって、その製品の具体的な仕様を発表した。製品名は「Virtex-7 HT」である。2012年の前半に出荷を始める予定だ。
28Gビット/秒の高速シリアルトランシーバの集積数が16チャネルの最大規模品「XC7VH870T」のほか、8チャネル集積の「XC7VH580T」と4チャネル集積の「XC7VH290T」、合わせて3品種を用意する。各品種ともに、28Gビット/秒の高速シリアルトランシーバに加えて、13Gビット/秒の高速シリアルトランシーバも24チャネル〜72チャネル搭載する。これらを合わせると、入出力の総帯域幅は最大規模品で2.77Tビット/秒(入力と出力がそれぞれ約1.38Tビット/秒)に達する計算だ。
この最大規模品を使えば、今後開発が進むと期待される400Gビット/秒のラインカードに1個のFPGAで対応可能になる(図2)。ネットワーク側のインタフェースは、例えば「OTU(Optical- channel Transport Unit) 4」規格に対応する100Gビット/秒動作の光トランシーバモジュールを4個、28Gビット/秒の16チャネルを使って接続できる。ライン側/クライアント側につながるネットワークプロセッサ(NPU)やASICとのインタフェースは、13Gビット/秒の72チャネルを利用すればよい。
 図2 400Gビット/秒対応イーサネット用ラインカードの構成例 光トランシーバモジュールとの接続に物理層(PHY)チップを外付けする必要はない。FPGAに集積した28Gビット/秒の高速シリアルトランシーバを直接つなげる。出典:ザイリンクス
図2 400Gビット/秒対応イーサネット用ラインカードの構成例 光トランシーバモジュールとの接続に物理層(PHY)チップを外付けする必要はない。FPGAに集積した28Gビット/秒の高速シリアルトランシーバを直接つなげる。出典:ザイリンクス一方のアルテラは、2010年11月現在、28Gビット/秒の高速シリアルトランシーバを集積する製品の詳細はまだ明らかにしていない。「Stratix Vに関する追加発表あるいは詳細の開示は、これから2011年上旬までの期間で随時発表していく」(同社)。ただし、1個のFPGAに集積する28Gビット/秒トランシーバのチャネル数については、4チャネルになるとすでに公表している。最大規模品にともに集積する12.5Gビット/秒の高速シリアルトランシーバの32チャネル分を合わせても、入出力の総帯域幅は1.02Tビット/秒にとどまる。
このためザイリンクスは、「総帯域幅は当社の方が2.7倍も広い」と優位性を主張する。同社によれば、帯域幅が比較的狭いFPGAを複数個用意して相互接続することで帯域幅を広げる構成を採ると、利用できる入出力端子の数が制限されてしまうほか、FPGA間の信号の受け渡しによって遅延が生じ、システム全体として性能が制限されてしまうなどの課題があるという。
Virtex-7 HTが搭載する28Gビット/秒トランシーバ自体の特性については、OIF(Optical Internetworking Forum)が定める電気インタフェースの共通仕様「CEI-28G」に準拠する。試作チップでPRBS 31の疑似ランダムパターンを使ってアイパターンを観測したところ、ランダムジッターは315fs、トータルジッターは6psだったという(図3)。消費電力については、「まだ試作チップでの評価段階のため、現時点では公表できない。2011年の第1四半期に公表する予定だ」(同社)と説明している。
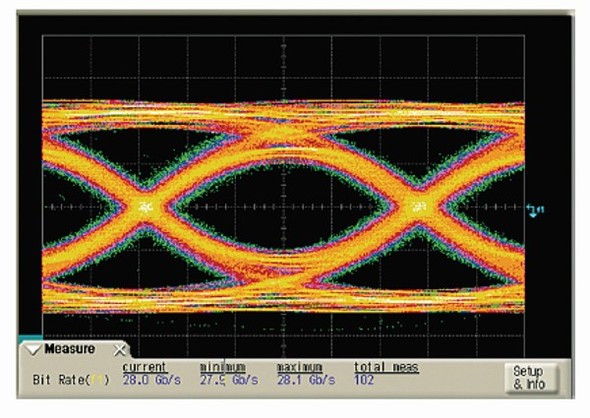 図3 28Gビット/秒トランシーバのアイパターン ザイリンクスの試作チップで観測した伝送波形である。位相雑音を低く抑えられるLCタンク型PLLを採用したほか、DFE方式の波形補正回路を搭載したり、デジタル回路部からの雑音の侵入を防ぐ独自の工夫を施すことでジッターを低減したという。アイパターンの開口は良好である。出典:ザイリンクス
図3 28Gビット/秒トランシーバのアイパターン ザイリンクスの試作チップで観測した伝送波形である。位相雑音を低く抑えられるLCタンク型PLLを採用したほか、DFE方式の波形補正回路を搭載したり、デジタル回路部からの雑音の侵入を防ぐ独自の工夫を施すことでジッターを低減したという。アイパターンの開口は良好である。出典:ザイリンクスなおアルテラは、28Gビット/秒トランシーバの消費電力について、2010年4月の時点ですでに「チャネル当たり200mW、1Gビット/秒当たりに換算すると7mWだ」と説明しており、2010年11月現在もこの数字に変更はないという。このほか、ジッターなど電気的な特性については、ザイリンクスと同様に、CEI-28Gに準拠すると述べている。
新興ベンダーが微細化で初の逆転劇
最大手2社が28nm世代品の詳細を次第に明らかにする中、2004年設立の新興ベンダーであるアクロニクスセミコンダクターから興味深い発表が2010年11月にあった。インテルから22nm世代のプロセス技術の提供を受けることで、アクロニクスとインテルが「戦略的提携」を締結したというのだ。具体的には、インテルが半導体ファウンドリとして、アクロニクスが設計したFPGAの製造を請け負う。22nm世代を皮切りに、その先のプロセス世代もこの提携関係を継続的に維持することで合意しているという。
アクロニクスの会長兼社長を務めるJohn Lofton Holt氏は、「FPGAの市場では、1980年代以降現在に至るまで、ザイリンクスとアルテラが明らかなリーダー企業として市場をけん引してきた。当社のような新興企業が技術的なリーダーシップを取るのは、FPGAの歴史で初めてだ」と語る。
すでに22nm世代品の早期の開発に着手しており、2011年第3四半期にテープアウトする(設計を完了して製造に着手する)予定だという。同年第4四半期には、サンプルチップの出荷を開始する計画だ。
性能をより重視した「Speedster22i-HP」と、集積規模をより重視した「Speedster22i-HD」の2つの製品群を用意する(図4)。HPでは、1.5GHzの動作周波数を実現し、HDではASICゲート換算で最大2500万ゲート、4入力ルックアップテーブル(LUT)換算で最大250万LUTの品種を提供するという。28Gビット/秒の高速シリアルトランシーバや各種MAC層処理回路をハードIPとして混載する品種も用意すると述べており、ザイリンクスやアルテラの次世代ハイエンドFPGAと真っ向ぶつかる用途も視野に入れる。
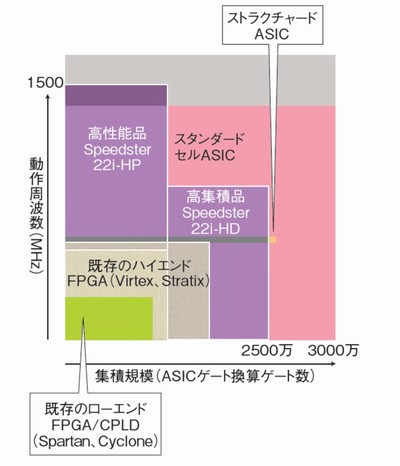 図4 アクロニクスが22nm技術で描く製品マップ インテルの22nmプロセス技術を利用することで、性能と集積規模の両方で最大手ベンダーのFPGAをしのぐ製品を実現できるという。スタンダードセル方式のASICが主流だった領域も視野に入れている。出典:アクロニクスセミコンダクター
図4 アクロニクスが22nm技術で描く製品マップ インテルの22nmプロセス技術を利用することで、性能と集積規模の両方で最大手ベンダーのFPGAをしのぐ製品を実現できるという。スタンダードセル方式のASICが主流だった領域も視野に入れている。出典:アクロニクスセミコンダクターただしFPGA市場は、FPGAチップだけを供給すればよいというわけではない。例えチップ自体が優れていても、開発ツールやIPコアのほか、ユーザーのアプリケーション開発をサポートする体制など、包括的な環境が整っていなければ、採用は進まない。アクロニクスがハイエンドFPGA市場の「第3極」になるのは、それほど簡単ではないだろう。しかし、その取り組みは間違いなく注目に値する。
不揮発FPGAも65nmに微細化
中堅ベンダー2社が手掛ける不揮発性FPGAでも微細化が一気に進む。
マイクロセミ(旧アクテル)は、製造技術に65nm世代のフラッシュメモリ混載プロセスを採用することで、130nmプロセスの既存品に比べて、ユーザーロジックの集積規模を1桁増やすとともに、性能を2倍に向上させると2010年11月に発表した。すでに65nm世代品の最初のテープアウトを終えており、チップが手元にあるという。
集積規模については、130nm世代の既存品は最大規模の品種が300万ゲート(4入力LUT換算で3万個)規模だったのに対し、次世代品では「数千万ゲート(数十万LUT)規模の品種を用意できる」(同社)という。性能については、品種によって異なるので一概に言えないとして、具体的な動作周波数の明言は避けた。「具体的な製品については、2011年に改めて発表する」(同社)。
このほか65nm世代品では、消費電力の低減を進める。130nmから65nmに微細化することで、動作時の消費電力を65%低減する。さらに、既存品から搭載していた「Flash*Freeze」と呼ぶ待機モードを改良し、待機時の静的な消費電力を大幅に抑えた(図5)。
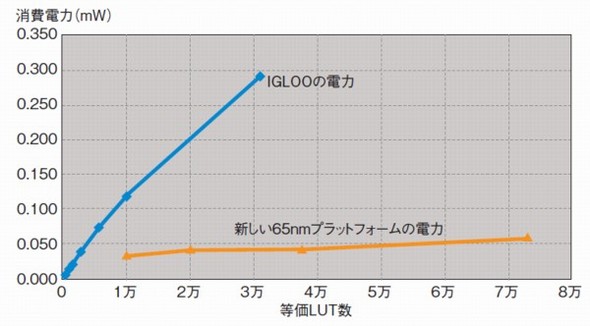 図5 不揮発FPGAの待機時消費電力をいっそう低減 Flash*Freezeは、FPGAのコア部の電源は遮断せず、レジスタやSRAMのデータを保持するモードだ。この図では、65nm技術を適用する次世代品と130nm世代の既存品「IGLOO」で、Flash*Freezeモードにおける待機時消費電力を比較した。既存品では、集積規模に比例して消費電力が増大していたが、次世代品では集積規模が増えても消費電力はそれほど増加しない。出典:マイクロセミ
図5 不揮発FPGAの待機時消費電力をいっそう低減 Flash*Freezeは、FPGAのコア部の電源は遮断せず、レジスタやSRAMのデータを保持するモードだ。この図では、65nm技術を適用する次世代品と130nm世代の既存品「IGLOO」で、Flash*Freezeモードにおける待機時消費電力を比較した。既存品では、集積規模に比例して消費電力が増大していたが、次世代品では集積規模が増えても消費電力はそれほど増加しない。出典:マイクロセミこの次世代フラッシュFPGAで狙う市場については、「地上」と「宇宙」の大きく2つに分けて説明する。人工衛星などの「宇宙」用途は、旧アクテルが従来から得意としていた市場だ。「飛行制御やモーターや太陽電池パネルなどの制御では、すでにほとんどの人工衛星が旧アクテルのFPGAを採用している。ただし、制御に比べて高い性能と大きな集積規模を求めるデータ処理では、ASICを利用することがほとんどだった。次世代品は、そうしたASICの置き換えに使える」(同社)。反対に「地上」用途では、データ処理ではなく、制御やセンシングの用途を狙う。「通信機器などのデータ処理は、ザイリンクスやアルテラが供給するSRAMベースのFPGAの独壇場である。当社のフラッシュFPGAは、それとは異なり、低い消費電力や、高いセキュリティと信頼性を求めるセンシングや制御の用途に適している」(同社)。
不揮発「PLD」でローエンドFPGAを置き換え
ラティスセミコンダクターは、プログラマブル論理セル群の集積規模が比較的小さい「ローデンシティー」タイプの不揮発性PLD(Programmable Logic Device)の新世代品「MachXO2」を2010年11月に発表した。65nm世代のフラッシュメモリ混載プロセスで製造することで、130nm世代で製造していた従来品「MachXO」に比べて、論理セル群の集積規模を3倍、内蔵メモリの容量を10倍にそれぞれ高めつつ、待機時の消費電力を大幅に低減し、集積規模当たりの価格を30%引き下げる。
従来品に比べて論理セル群の集積規模が増大したことから、従来品では競合することが難しかった、「ザイリンクスやアルテラ、旧アクテルの各社のローエンドFPGAの市場を狙える」(ラティスセミコンダクター)という。さらに、消費電力や価格を低減したことから、「回路規模が比較的小さいASICを置き換えたり、単機能ICにASSPを組み合わせて構成していた回路をこのPLD1個に置き換えたりといった用途も期待できる」(同社)。
論理セル群の集積規模は、LUT数換算で256LUT〜7000LUT。内蔵メモリの容量は、組み込みRAMが最大240Kビット、分散RAMが最大54Kビット、ユーザー用のフラッシュメモリが最大256Kビットである。一部品種については、すでに早期サンプルの供給を始めており、今後、エンジニアリングサンプルを2010年12月、量産品を2011年3月に出荷する予定。残る品種についても順次サンプル出荷し、2011年第3四半期(7月〜9月)までには全品種の量産を開始する計画である。
なお同社は、今回のMachXO2を、「FPGA」でも「CPLD」でもなく「PLD」と呼んでいる。実際にMachXO2は、FPGAとCPLDの両方の特性を兼ね備える。すなわち、論理セルの基本的なアーキテクチャについては、一般的なFPGAと同様にLUTを利用しており、マクロセルベースの旧来型CPLDとは異なる。一方で使い勝手については、前述の通りフラッシュメモリ混載プロセスで製造することで不揮発性を実現しており、電源をオン/オフしても論理セル群のコンフィギュレーションを維持できる点でCPLDと同じだ。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- 重量はクジラ級! 超巨大な高NA EUV装置の設置をIntelが公開
- JDI、次世代有機ELディスプレイ「eLEAP」を24年12月に量産開始へ
- 2023年の世界半導体売上高ランキングトップ20、NVIDIAが初の2位に
- 中国政府の「Intel/AMD禁止令」、中国企業への強い追い風に
- パワー半導体向けウエハー市場、2035年に1兆円台へ
- 「GPT-4」を上回る性能で、グラフィカルな文書を読解するLLM技術
- どうする? EVバッテリー リサイクルは難しい、でもリユースにも疑問
- Intelが高NA EUV装置の組み立てを完了、Intel 14Aからの導入に向けて前進
- 全固体ナトリウム電池の量産化に向けた新合成プロセスを開発、大阪公立大
- TSMC、24年Q1は増収増益 地震の影響は「最小限にとどまる」
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。