開き直る人工知能 〜 「完璧さ」を捨てた故に進歩した稀有な技術:Over the AI ―― AIの向こう側に(14)(5/9 ページ)
音声認識技術の基礎
さて、ここからは、音声認識技術の1つとして、メル周波数ケプストラム係数(MFCC)を利用した方式を、恐しく簡単に説明します(なお、MFCCの名前は忘れていただいて結構です)。
最初に、どんな会話であろうとも、まずは「音節」としてぶった切らなければ、話は始まりません。どんな言語で会話しようとも、結局のところは音節の集合体だからです。
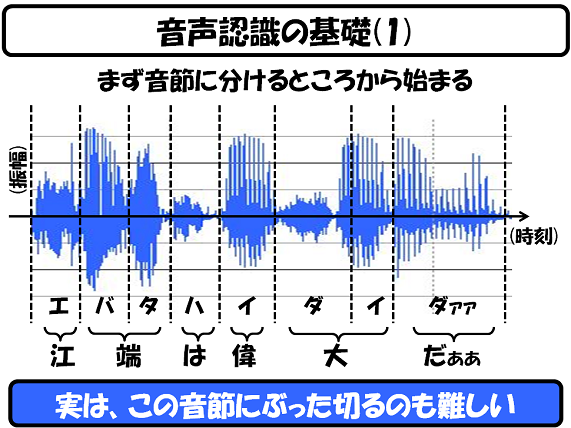
ところが、この音節にぶった切るのが、結構難しいのです。上記の「ダァァ」が「ダァァァァァァァ」と長くなった場合に、コンピュータは、どこで音節が切れるのかを判断することができません。この問題に対処する技術の1つにHMM(Hidden Markov Model(隠れマルコフモデル))というものがあるのですが、今回は割愛します(面倒だから)。
次に、この1つの音節を取り出して、この音節の周波数スペクトルを読み取ります。
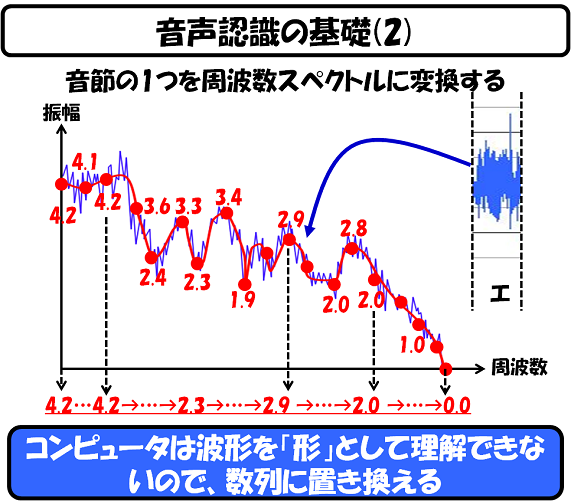
先ほど申し上げた通り、音声は単音の集合体ですが、単音の周波数は連続値(×離散値)をとなるので、結局のところ、こんな形になってしまいます。そして、コンピュータは波形を、波形のまま理解することができないので、適当な周波数の間隔の値を拾って覚えておきます。
上記の例で、12個の値を拾う場合には、12次元のベクトル値として記憶しておきます。
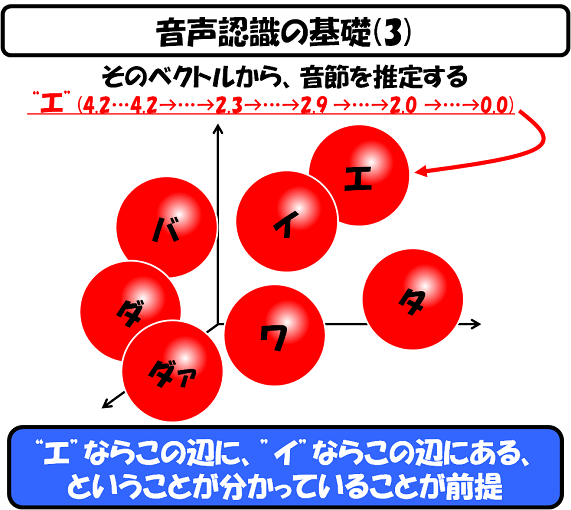
さて、この12次元のベクトルを、12次元上の過去のデータと照合します。上記は3次元のイメージで記載されていますが、実際は12次元あるものとして考えてください。
そのベクトルが"エ"の球の中に含まれているなら、「多分、その音節は"エ"に違いない」という風に、一つ一つ音節を決定していきます。
当然の事ながら、このような球を作るためには、膨大な"エ"の発音を、多くの人に発音してもらって、データベース化しなければ、何も始めることができません。「音声認識技術」では、このようなサンプルを集める地道で苦痛な作業を避けて通れないのです。
しかも、その"エ"が、その球の中に必ず入るという保証もありません。そのような場合、この方法による音節の抽出は、100%失敗します。
このように、「音声認識技術」は、恐しく面倒で地道な努力を続ける割に、その努力に比例してその認識率が向上する訳でもないという、研究者やエンジニアにとっては、苦痛に満ちた研究開発が必要となっていたのです。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- 重量はクジラ級! 超巨大な高NA EUV装置の設置をIntelが公開
- どうする? EVバッテリー リサイクルは難しい、でもリユースにも疑問
- パワー半導体向けウエハー市場、2035年に1兆円台へ
- 2023年の世界半導体売上高ランキングトップ20、NVIDIAが初の2位に
- 「GPT-4」を上回る性能で、グラフィカルな文書を読解するLLM技術
- Intelが高NA EUV装置の組み立てを完了、Intel 14Aからの導入に向けて前進
- 中国政府の「Intel/AMD禁止令」、中国企業への強い追い風に
- JDI、次世代有機ELディスプレイ「eLEAP」を24年12月に量産開始へ
- Intelの最新AI戦略と製品 「AIが全てのタスクを引き継ぐ時代へ」
- TSMC、24年Q1は増収増益 地震の影響は「最小限にとどまる」
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。