忖度する人工知能 〜権力にすり寄る計算高い“政治家”:Over the AI ―― AIの向こう側に(20)(4/11 ページ)
もしも桶屋の社長がソフトウェアエンジニアだったなら
ですが、もし、桶を作る社長が、(A)優れたソフトウェアエンジニアであり、(B)AI技術の知見に精通しており、さらに、(C)桶が売れる可能性に関わる世界の全ての状況を「状態」と「行動」として定義でき、かつ、(D)それをソフトウェア上で実装できる ―― と仮定(後述しますが、こんな人間は存在し得ません)した場合、どうなるのでしょう。
強化学習(のQ学習)とは、ザックリ以下のような仕組みになってます。
まず、「桶が売れる」に至ることのできる世界に至る、全ての「状態」と、その状態を次の状態に変化させる「行動」を定義します。
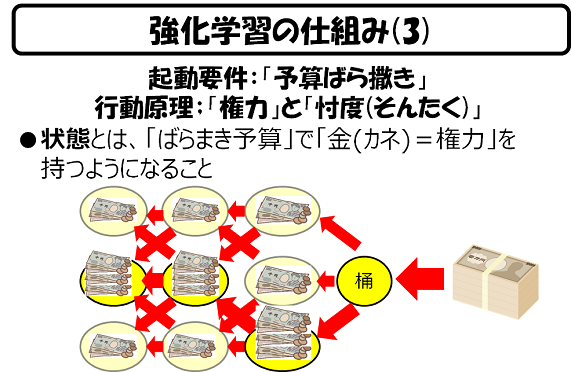
そして、「桶が売れる」という状態(これを、「桶の状態」ということにします)に至れた「行動」に対して、「桶の状態」は、お金を支払います。その結果、「桶の状態」に至ることに貢献した「その前の状態」は、お金を受け取ることができます。
「その前の状態」は、さらにその状態に至ることに貢献してくれた、「その前の前の状態」に、お金を支払います。これが、さらに「その前の前の前の状態」……と続きます。
そして、このお金、不思議なことに「どんなに支払っても、減らない」魔法のお金であることを覚えておいてください。
さて次に、「行動」です。「行動」はお金持ちが大好きです。ですので、「行動」は、お金持ちに成り上がった「次の状態」に状態を変化させるように働きます。
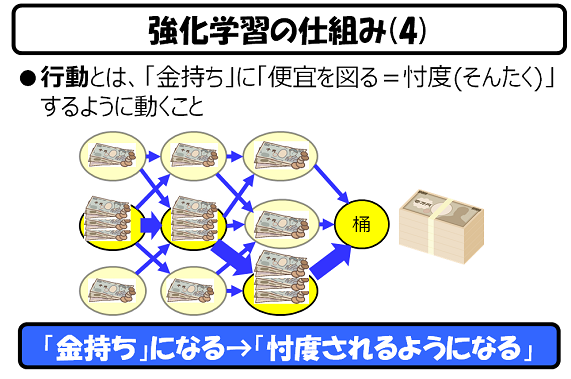
ただ、この「行動」は、狡猾(こうかつ)な奴で、常に「金持ち」をチヤホヤするだけではなく、「貧乏人」にも、小さい確率で移動するように行動します。将来、その状態が、「金持ち」になった時に、「あ、しまった」とならないように、ちゃんと「コネ」を作っておくためです。
これは、企業が政治献金を行う時に、与党へはもちろん、弱小野党へも、額が小さくても献金を怠らないこととよく似ています(政権がひっくり返っても、コネがあれば、なんとかなります)。
で、この「状態」と「行動」を、山ほど(ケースにもよりますが、数百回から1億回までさまざま)繰り返します。繰り返さないと、「お金」が貯まりませんし、お金が貯まらないと「権力」が発生しないからです。
さて、こうして強化学習のQ学習を俯瞰してみると、この仕組みが、実に単純な政治の利益誘導モデル(「予算ばらまき」と、「(金による)権力」と「権力への忖度」)で動いていることが理解頂けるかと思います。
もっとも、AI技術の世界では、当然、Q学習を「権力/忖度モデル」などとは言わず、「報酬型学習」と言います。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- 半導体製造の最先端を独走するTSMCの決算から読み取れること
- ハイエンドスマホのプロセッサはどこまで進化した? 最新モデルで読み解く
- 信越化学、三益半導体工業を完全子会社に 総額680億円
- 「VLSIシンポジウム2024」は投稿論文が40%増で激戦に、中国が躍進
- ルネサス、24年1Qは予想比上振れ 車載マイコンのシェア低下も「悲観しない」
- どうする? EVバッテリー リサイクルは難しい、でもリユースにも疑問
- 「指輪でタッチ」で簡単お支払い ドコモがスマートリング発売へ
- 抵抗器の電蝕対策
- 重量はクジラ級! 超巨大な高NA EUV装置の設置をIntelが公開
- 空間に溶け込む一体感 TOPPANの新ディスプレイ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。