EE Times Japan >
先端技術 >
NEC、半分の学習データ量で済む深層学習技術:苦手な学習データを集中的に生成
NECは、学習データ量が従来のほぼ半分でも、高い識別精度を維持できるディープラーニング(深層学習)技術を開発した。
» 2019年08月22日 10時30分 公開
[馬本隆綱,EE Times Japan]
専門家によるデータ生成の調整も不要
NECは2019年8月、学習データ量が従来のほぼ半分でも、高い識別精度を維持できるディープラーニング(深層学習)技術を開発したと発表した。多くの学習データを収集することが難しい、製品の外観検査やインフラ保全などの用途に向ける。
ディープラーニングを応用したシステムで、識別の精度を向上させるには、識別が難しい「苦手な学習データ」を、より多く学習することが効果的といわれている。従来は、「データ拡張」と呼ばれる手法で、データ量を人工的に増やしてきた。ところが、この方法だと高い効果が得られる苦手な学習データを生成するまでに至らなかったという。
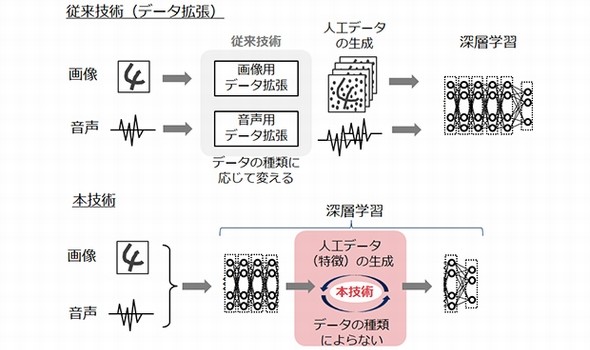 従来技術(データ拡張)と、今回開発した技術の違い 出典:NEC
従来技術(データ拡張)と、今回開発した技術の違い 出典:NEC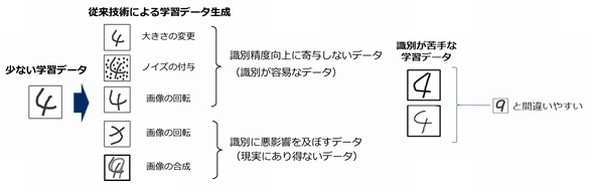 従来技術では識別が苦手な学習データを生成するのは難しい 出典:NEC
従来技術では識別が苦手な学習データを生成するのは難しい 出典:NECそこでNECは、ニューラルネットワークの中間層で得られる特徴量を意図的に変化させ、識別がしにくい「苦手な学習データ」を、集中的に人工生成させ、識別精度を高めることに成功した。手書き数字認識や物体認識の公開データベースを用いて、開発した技術を評価したところ、学習データ量が半分でも、識別精度は従来技術と変わらないことが分かった。

また、ニューラルネットワーク内部の数値に基づき、自動的に学習データを生成することが可能だ。このため、さまざまなデータに対し汎用的かつ効率良く適用することができる。データの種類が異なっても、従来のように専門家がデータ生成方法を調整する必要はないという。
関連記事
 “データの意味を推定”するAI、NECが開発
“データの意味を推定”するAI、NECが開発
NECは、さまざまなデータシートに記載された数値の意味を推定するAI(人工知能)技術「データ意味理解技術」を開発した。専門家でも1カ月要していたデータ統合作業を、わずか1時間に短縮できるという FPGAでエッジAIを高速に、NECが専用ツールをデモ
FPGAでエッジAIを高速に、NECが専用ツールをデモ
NECは「第8回 IoT/M2M展」(2019年4月10〜12日、東京ビッグサイト)で、FPGAを使った高速画像判定や、顔が写っていなくても人物を照合できる技術、推論を高速化する「NEC AI Accelerator」などを展示した。 2023年までに量子コンピュータの実用化を目指すNEC
2023年までに量子コンピュータの実用化を目指すNEC
NECは、2023年までに、1ミリ秒と長いコヒーレント時間を持つアニーリング型量子コンピュータ(量子アニーリングマシン)を本格的に実用化すべく、開発を進めている。 NEC、MI活用で熱電変換材料の出力密度を向上
NEC、MI活用で熱電変換材料の出力密度を向上
NECは、「nano tech 2019」で、AI(人工知能)技術を駆使して新材料を探索する「マテリアルズインフォマティクス(MI)」や、極めて高速に組み合わせ最適化を実現する「量子コンピュータ」などの研究成果を紹介した。 NEC、顔画像のみに頼らない人物照合技術を開発
NEC、顔画像のみに頼らない人物照合技術を開発
NECは、カメラに映った服装や体型からでも人物を照合できる技術を開発した。多くの人物や遮る物があって、照合したい人物の顔や体の一部が確認できない場所でも、全身の外観画像を用いて同一人物かどうかを判定することが可能となる。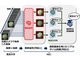 NECと東大、カメラで高速かつ高精度に物体認識
NECと東大、カメラで高速かつ高精度に物体認識
NECと東京大学の研究グループは共同で、「高速カメラ物体認識技術」を開発した。撮影した大量の画像データから、不具合のある製品などを高速かつ高精度に判別することができる。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- 重量はクジラ級! 超巨大な高NA EUV装置の設置をIntelが公開
- どうする? EVバッテリー リサイクルは難しい、でもリユースにも疑問
- パワー半導体向けウエハー市場、2035年に1兆円台へ
- 2023年の世界半導体売上高ランキングトップ20、NVIDIAが初の2位に
- 「GPT-4」を上回る性能で、グラフィカルな文書を読解するLLM技術
- Intelが高NA EUV装置の組み立てを完了、Intel 14Aからの導入に向けて前進
- 中国政府の「Intel/AMD禁止令」、中国企業への強い追い風に
- JDI、次世代有機ELディスプレイ「eLEAP」を24年12月に量産開始へ
- Intelの最新AI戦略と製品 「AIが全てのタスクを引き継ぐ時代へ」
- TSMC、24年Q1は増収増益 地震の影響は「最小限にとどまる」
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。