IC設計にもAIを、配置配線が機械学習で加速化する:ISSCC 2020(2/2 ページ)
学習済みのAIを、別の分野に応用できるのか
自動運転や医療画像、囲碁などのAIアプリケーションはそれぞれ、学習専用のAIシステムを微調整して作られている。基本的に、1つのアプリケーションにつき1種類のAIを使用する。ここで、「ある分野を学習したAIを使用して、その学習内容をよく似た別のタスクに適用できるのか」という疑問が生じる。
Dean氏は、「この問題を取り上げたのは、ASIC設計で、配置配線にMLを用いることが検討され始めてきたからだ。配置配線は、囲碁よりもはるかに規模が大きい。囲碁のように明確なゴールがあるわけではないが、問題の規模が大きいのだ」と述べる。
Googleは、配置配線向けの学習モデルを作成し、ツールを使った一般化が可能かどうかを試した。1つの設計上で学習した内容を利用して、初めて目にする新しい設計に適用することができるのだろうか。その答えは、疑問の余地なく「イエス」だった。
さらにDean氏は、「これまで実験を行った全てのブロックにおいて、超人的な結果を得ることができた。少しずつ優れた成果を出しながら、時々人間をはるかに超える力を発揮する場合がある」と続ける。
この“優れた成果”の中には、配置配線を桁外れに短い時間で実行することができるという点も含まれる。エンジニアがそのタスクを達成しようとすると、何週間もの期間を要することになる。Dean氏の報告によると、MLを使った場合、同じタスクが24時間以内に完了し、しかも配線の長さが短くなったケースもあったという。さらに、自動化された配置配線ツールと比べても優れた成果を上げている(詳細は、米国EDNのこちらの記事から確認できる)。
またDean氏は、「MLの活用は、IC設計プロセスの他の部分にも拡大していくのではないか。例えば、HLS(高位合成)を向上させて、高水準記述から最適化された設計を実現することなどが考えられる」と述べる。
Dean氏は、「MLモデルは将来的に、どのようなものになるのか。1つのモデルをトレーニングして、類似したタスクに対して一般化することは可能なのだろうか。理想としては、1つのモデルで、数千〜数百万個のタスクを実行することを学習できるようにしたい」と述べている。
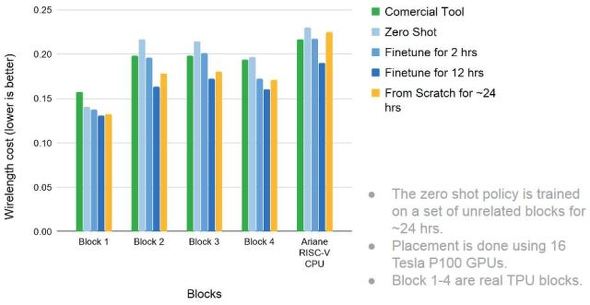 Googleが公開した、ASICの設計にMLを応用した際の結果。幾つかのブロックと、RISC-VベースのCPU「Ariane」について検証した。同じMLモデルを学習させ、それによって設計の効率がどのくらい向上するかを比較している 出典:Google
Googleが公開した、ASICの設計にMLを応用した際の結果。幾つかのブロックと、RISC-VベースのCPU「Ariane」について検証した。同じMLモデルを学習させ、それによって設計の効率がどのくらい向上するかを比較している 出典:GoogleエッジAIの加速が、新しいカテゴリーのプロセッサを生み出す
MediaTekでシニアバイスプレジデント兼CSO(最高戦略責任者)を務めるKou-Hung “Lawrence” Loh氏は、AIが現在、インターネットに接続されているほぼ全てのものをどのように変化させているのかという点を取り上げ、「AIoTは、既存の数百億台ものデバイスから急速に拡大することにより、2030年までには、約3500億台のデバイスを網羅するようになる見込みだ」と述べている。
AIは現在、エッジ方向に向かって移動している。その理由としては、エッジでのAI活用が可能になってきているからという点が一つ。また多くの場合、例えばデータセンターで増大している処理負荷を軽減したり、ネットワーク上のトラフィックを削減したりする上で、必要とされているという理由もある。さらに、一部のアプリケーションは、ローカル処理を必要とし、それによって最もうまく機能するからという点も挙げられる。
ローカル処理に求められるのは、高速化を実現すること、AI専用として設計されていること、エネルギー効率が極めて高いことなどである。
これらは本質的に、新しいカテゴリーのプロセッサだといえる。Loh氏はこれを、「APU(AI Processing Unit)」と呼ぶが、その他にも、「NPU(ニューラルプロセッシングユニット)」や、「BPU(Brain Processing Unit)」などの名前で呼ばれることもある。例えばAPUは、CPUと比べると柔軟性の面では劣るが、特定用途向けに開発されているため、約20倍の高速化を実現し、消費電力量は55分の1に低減することが可能だという。
MediaTekの研究者たちはISSCCにおいて、別の論文を発表し、7nmプロセス適用の5Gスマートフォン用SoC(System on Chip)の汎用AIアプリケーション向けに、3.4〜13.3TOPS/Wを実現するデュアルコアディープラーニングアクセラレーターについて提案していたが、これは決して偶然ではない。
これは、7nmプロセスに関する論文である。ムーアの法則、プロセス技術微細化の曲線に沿って競争が進めば、少なくともあともう一歩、既存の7nmから5nmまで、性能向上を達成することが可能だ。Loh氏は、「ムーアの法則は、まだ通用する」と述べる。
しかし、注意点がないわけではない。同氏は、「トランジスタの集積数は、引き続き典型的なムーアの法則に沿って進んで行くだろう。しかし、1トランジスタ当たりのコストはムーアの法則通りにはいかない。さらに、半導体チップ設計の複雑化に伴い、処理工程もさらに複雑化して、最新デバイスのコストが急増すると、小規模メーカーはその技術を使うことができなくなる。その上、歩留まりの問題もある」と述べる。
Loh氏は、「こうしたさまざまな問題に対する共通の解決策は、ダイの分割だ。これは現実問題として、チップレット技術などの手法を採用するということを意味する。ムーアの法則よりも優れた成果を上げられるのではないだろうか」と語った。
【翻訳:田中留美、編集:EE Times Japan】
関連記事
 エッジAIこそ日本の“腕の見せどころ”、クラウドとの連携も鍵
エッジAIこそ日本の“腕の見せどころ”、クラウドとの連携も鍵
今回は、業界で期待が高まっている「エッジコンピューティング」を解説する。AWS(Amazon Web Service)やMicrosoft、半導体ベンダー各社も、このトレンドに注目し、取り組みを加速している。 米Gyrfalconの超省電力AIチップ、12.6TOPS/Wを実現
米Gyrfalconの超省電力AIチップ、12.6TOPS/Wを実現
米Gyrfalcon Technology(以下、Gyrfalcon)は、民生機器向けの新しいAI(人工知能)アクセラレーター「Lightspeeur 5801」を発表した。同社にとって第4世代のAIアクセラレーターとなり、既にLG Electronicsのミッドレンジスマートフォン「Q70」に搭載され、“ボケ”などのカメラエフェクトの推論処理に使われている。 戦いの火ぶたが切られたエッジAI市場
戦いの火ぶたが切られたエッジAI市場
人工知能(AI)は過去2年間で、世界的なメガトレンドへと変化した。機械学習は、消費者や自動車、産業、エレクトロニクス全般など、ほぼ全てに何らかの形で影響をもたらしている。さらに、私たちがまだ、うかがい知れない方法で社会や生活に影響を与えると思われる。 ディープインサイト、組み込み型エッジAIを提供
ディープインサイト、組み込み型エッジAIを提供
ディープインサイトは、IoT端末側で学習と推論の両方に対応可能な、組み込み型エッジAI「KAIBER engram(カイバー エングラム)」のライセンス供給を始めた。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- 2023年の世界半導体売上高ランキングトップ20、NVIDIAが初の2位に
- 中国政府の「Intel/AMD禁止令」、中国企業への強い追い風に
- 就業人員の4割が帰還組、ルネサス甲府工場が10年の時を経て再稼働
- 日本伝統の「和装柄」がヒントに 半導体の高度な熱管理につながる技術
- ルネサス甲府工場がいよいよ再稼働 柴田社長「パワー半導体の戦略的拠点に」
- Raspberry PiがAIカメラモジュール発売へ、ソニーのAI処理機能搭載センサー採用
- 半導体製造装置の販売額、2023年は1063億ドルで前年比1.3%減
- 「FinFETの終えん」に備える 今後10年でGAAへの移行が加速?
- Rapidus、シリコンバレーに新会社設立 AI半導体の顧客開拓を加速
- 2024年はDRAM/NAND市場が回復へ 需給バランスも正常化
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。